
进入2025年,国内车市智能化竞争进一步升级,一些车企开始喊出“全民智驾”的口号。而从技术层面来说,处在头部位置的车企已经在推动下一代自动驾驶架构的落地。
在3月18日的NVIDIA GTC 2025上,理想汽车自动驾驶技术研发负责人贾鹏发表了主题为《VLA:迈向自动驾驶物理智能体的关键一步》的演讲,并发布了理想汽车的下一代自动驾驶架构——MindVLA。

理想汽车董事长兼CEO李想当日在社交平台发文称,“MindVLA是一个视觉-语言-行为大模型,但我们更愿意将其称为“机器人大模型”,它将空间智能、语言智能和行为智能统一在一个模型里,让自动驾驶拥有感知、思考和适应环境的能力,是我们通往L4路上最重要的一步。”他还表示,MindVLA能为自动驾驶赋予类似人类的驾驶能力,就像iPhone 4重新定义了手机,MindVLA也将重新定义自动驾驶。
全栈自研,MindVLA开启自动驾驶iPhone 4时刻
理想汽车的智能驾驶经过几次迭代和升级。去年10月,理想汽车全量推送“端到端+VLM”双系统方案后,该模式渐渐成为行业的标杆。许多企业开始采用这一路线。特别值得一提的是,不仅在自动驾驶领域,在通用机器人领域该系统也得到应用。
基于上述“端到端+VLM”双系统架构的实践,及对前沿技术的洞察,理想自研了MindVLA大模型。VLA是机器人大模型的新范式,其将赋予自动驾驶强大的3D空间理解能力、逻辑推理能力和行为生成能力。
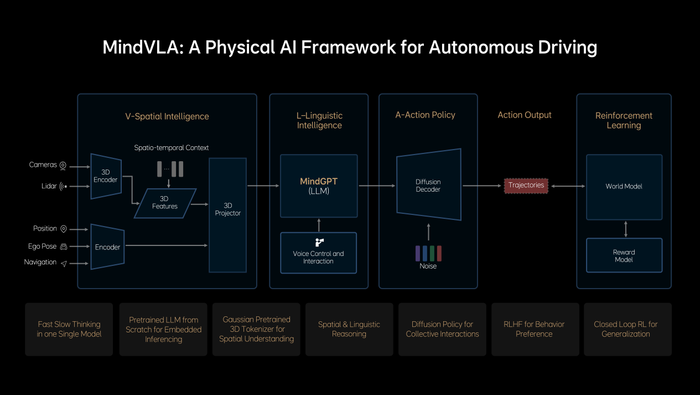
值得注意的是,MindVLA不是简单地将端到端模型和VLM模型结合在一起,所有模块都是全新设计。3D空间编码器通过语言模型后,和逻辑推理结合在一起后,给出合理的驾驶决策,并输出一组action token(动作词元),action token指的是对周围环境和自车驾驶行为的编码,并通过diffusion(扩散模型)进一步优化出最佳的驾驶轨迹,整个推理过程都要发生在车端,并且要做到实时运行。
2010年中发布的iPhone 4是智能手机时代的首个爆款,也是智能手机渗透率加速提升的起点。对汽车行业来说,理想汽车最新的MindVLA也将重新定义自动驾驶,加速行业的快速发展。
从用户体验方面来看,有MindVLA赋能的汽车不再只是一个简单的驾驶工具,而是一个能与用户沟通、理解用户意图的智能体。能够听得懂、看得见、找得到,是一个真正意义上的司机Agent或者叫“专职司机”。

所谓“听得懂”是用户可以通过语音指令改变车辆的路线和行为,MindVLA能够理解并执行“开太快了”“应该走左边这条路”等这些指令。“看得见”是指MindVLA具备强大的通识能力,不仅能够认识星巴克、肯德基等不同的商店招牌;当用户在陌生地点找不到车辆时,可以拍一张附近环境的照片发送给车辆,拥有MindVLA赋能的车辆能够搜寻照片中的位置,并自动找到用户。“找得到”意味着车辆可以自主地在地库、园区和公共道路上漫游,其中典型应用场景是用户在商场地库,可以跟车辆说:“去找个车位停好”,车辆就会利用强大的空间推理能力自主寻找车位,即便遇到死胡同,车辆也会自如地倒车,重新寻找合适的车位停下,整个过程不依赖地图或导航信息,完全依赖MindVLA的空间理解和逻辑推理能力。
对于人工智能领域而言,汽车作为物理人工智能的最佳载体,未来探索出物理世界和数字世界结合的范式,将有望赋能多个行业协同发展。
打破传统,六大关键技术引领行业创新
在理想交付端到端+VLM期间,空间智能、LLM、AIGC和具身智能等技术有了快速发展。基于此,理想开始思考能否将端到端模型和VLM模型合二为一,像GPT O1和DeepSeek R1一样,让模型自己学会快慢思考,同时赋予模型强大的3D空间理解能力和行为生成能力,将双系统的天花板进一步打开。
MindVLA打破了自动驾驶技术框架设计的传统模式,使用能够承载丰富语义,且具备出色多粒度、多尺度3D几何表达能力的3D高斯(3D Gaussian)这一优良的中间表征,充分利用海量数据进行自监督训练,极大提升了下游任务性能。
而在过去,从单目2D特征到单目3D特征,再到多摄像头的鸟瞰图(BEV)特征和占据网格(OCC)等不同阶段,大多依赖于监督学习,需要精准标注的数据,效率和数据利用率都很低下。
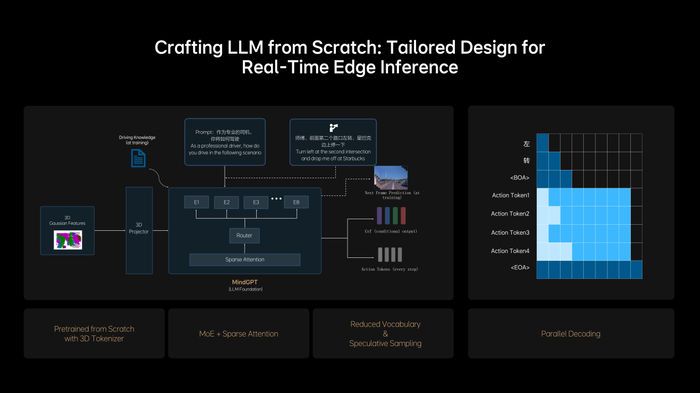
理想还从0设计和训练一个适合VLA的LLM基座模型,使其具备3D空间理解和推理能力,并能在有限资源下实现实时推理,保证模型规模增长的同时,不降低端侧的推理效率。而在训练模型去学习人类的思考过程,理想让快慢思考有机结合到同一模型中,并可实现自主切换快思考和慢思考。
为了把NVIDIA Drive AGX的性能发挥到极致,MindVLA采取小词表结合投机推理,以及创新性地应用并行解码技术,进一步提升了实时推理的速度。至此,MindVLA实现了模型参数规模与实时推理性能之间的平衡。
理想利用diffusion模型,将action token解码成最终的驾驶轨迹,并让RLHF与diffusion结合,学习和对齐人类行为的同时,提升安全下限。
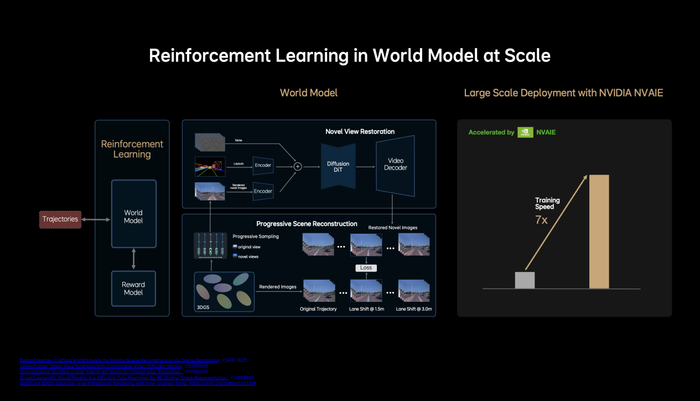
MindVLA基于自研的重建+生成云端统一世界模型,深度融合重建模型的三维场景还原能力与生成模型的新视角补全,以及未见视角预测能力,构建接近真实世界的仿真环境。源于世界模型的技术积累与充足计算资源的支撑,MindVLA实现了基于仿真环境的大规模闭环强化学习,即真正意义上的从“错误中学习”。过去一年,理想自动驾驶团队完成了世界模型大量的工程优化,显著提升了场景重建与生成的质量和效率,其中一项工作是将3D GS的训练速度提升至7倍以上。
理想通过创新性的预训练和后训练方法,让MindVLA实现了卓越的泛化能力和涌现特性,其不仅在驾驶场景下表现优异,在室内环境也展示出了一定的适应性和延展性。
持续精进,朝全球领先的AI企业再进一步
在上述六大技术的突破下,理想MindVLA能为自动驾驶行业带来革命性的变化。而这离不开理想在智能驾驶技术、AI大模型等领域的持续投入。

理想在不断进行技术创新的同时,还在人工智能领域顶级学术会议和期刊发表了大量论文,为加速技术发展贡献了重要力量。
李想曾说过,理想要做的不是汽车的智能化,而是人工智能的汽车化,并将推动人工智能普惠到每一个家庭。从行业视角来看,汽车将从工业时代的交通工具,进化成为人工智能时代的空间机器人。在对整个世界的理解上,理想通过人工智能将物理世界与数字世界进行融合,让有限的空间实现无限的延伸。




















































 47847
47847 26
26


 47847
47847 26
26


 48158
48158 46
46


 18095
18095 59
59


 76276
76276 17
17


 65573
65573 36
36


 63128
63128 4
4


 86478
86478 85
85


 30367
30367 78
78


 63524
63524 2
2


 62738
62738 4
4


 31856
31856 47
47


 71272
71272 50
50


 83067
83067 20
20


 99712
99712 97
97


 54978
54978 31
31


 63720
63720 90
90


 94331
94331 53
53


 29063
29063 54
54


 68942
68942 21
21

 89181
89181 94
94


 23218
23218 58
58


 28745
28745 52
52


 81201
81201 44
44


 17391
17391 69
69


 29549
29549 6
6


 17480
17480 70
70


 89028
89028 4
4


 98746
98746 88
88


 79267
79267 68
68


 83517
83517 81
81

 27017
27017 78
78


 54410
54410 77
77


 62398
62398 1
1


 63428
63428 58
58


 63473
63473 31
31


 47199
47199 19
19


 84052
84052 15
15


 46245
46245 22
22


 19684
19684 80
80


 22271
22271 49
49


 94874
94874 50
50


 36152
36152 35
35


 45060
45060 29
29


 74946
74946 99
99


 90160
90160 42
42


 41857
41857 2
2


 66369
66369 8
8


 47534
47534


 41
41

 52980
52980 33
33


 50061
50061 60
60


 68054
68054 69
69


 93840
93840 53
53


 92885
92885 11
11